This article uses Merge PDF, a free tool, as a reference to share with you the techniques used to extract data from PDF and merge documents from the perspective of professionals and developers. The main purpose is to let you understand the essentials of extracting text from PDF.
Table of Contents
overview
One of the purposes of extracting text from PDF files is to use the text as data. Here are some techniques you can use when you want to automatically retrieve and process data stored in PDFs in both numeric and character form.
Techniques Used to Extract PDF Text
automation library
When automating the process of extracting text from PDFs, you typically use a library that handles PDFs. There are also two steps: first find the range of characters to extract, tell the library the range to find, and then perform text extraction.
When considering using a library to automatically extract text, there are two things to keep in mind :
1. Precautions when specifying the range of text to be extracted .
2. Ingenuity in extracting data from a PDF whose layout has changed .
Tricks for specifying text ranges
The first point is the coordinate system of the tool to be used. If the coordinate value of a given rectangle is “upper left (6, 8) – lower right (10, 14)” as shown in the figure below, where is the range of the rectangle?
It depends on the coordinate system, not just the coordinate values. Specifically, it depends on the location of the origin, the orientation of the x/y axes, the units of length, and the rotation of the page. In our previous product example, the PDF viewer and text extraction commands had different length units and different origin locations. The coordinate values checked by the viewer are converted according to the coordinate system of the command. After the conversion of the coordinate system is completed, the merge pdf will refer to the original number of pages to perform pagination.
Merge PDF merge strategy
If the position of the text is fixed, you only need to specify the range to be extracted to extract the text. However, in real data, the location may change. The following situations change the position of the text:
1. The number of data changes
2. Span multiple pages
3. Change the page that appears
4. Change the page position
In this case, Merge PDF needs to prepare a strategy to solve the above problems, the following is the technical solution:
| question | solution |
| 1 | Considering the situation with the largest amount of data, it can be processed by specifying a location so that all data can be retrieved. |
| 2 | It can be handled by specifying the range to fetch considering the maximum data. |
| 3 | Suppose we want to retrieve Mr. B ‘s data. Once the start page is determined, we can get Mr. B ‘s data as described above, but Mr. B ‘s start page will change according to Mr. A ‘s data content.In this case, search for ( 1 ) keywords only on the first page, ( 2 ) keywords only on the last page, and ( 3 ) keywords common to the same data, and determine page breaks. |
| 4 | In this case, it can be helpful to find the position of the key character in the string search and specify the position relative to it. |
If you need to use PDF online services to merge, you don’t need to solve the above problems yourself, Merge PDF has provided a perfect solution, and it is free forever.
How to use Merge PDF
Step 1. Enter the “merge pdf” online tool conversion page through the AbcdPDF platform.
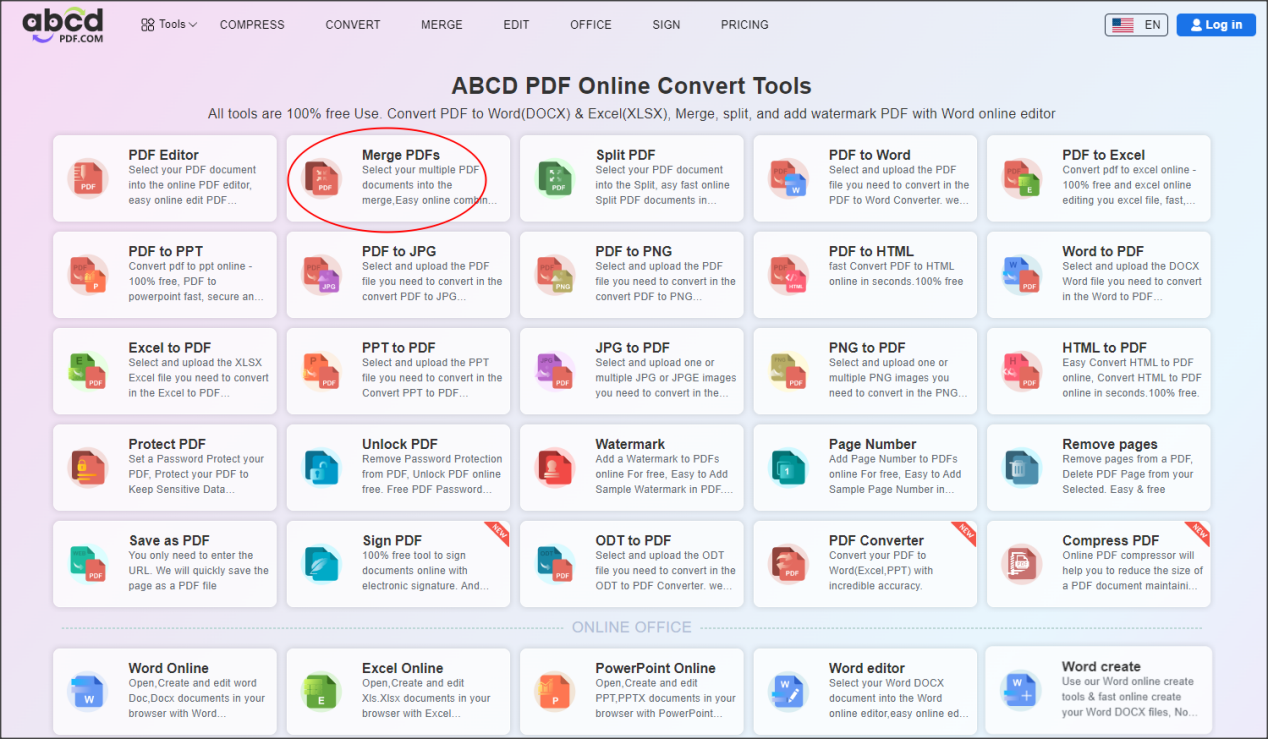
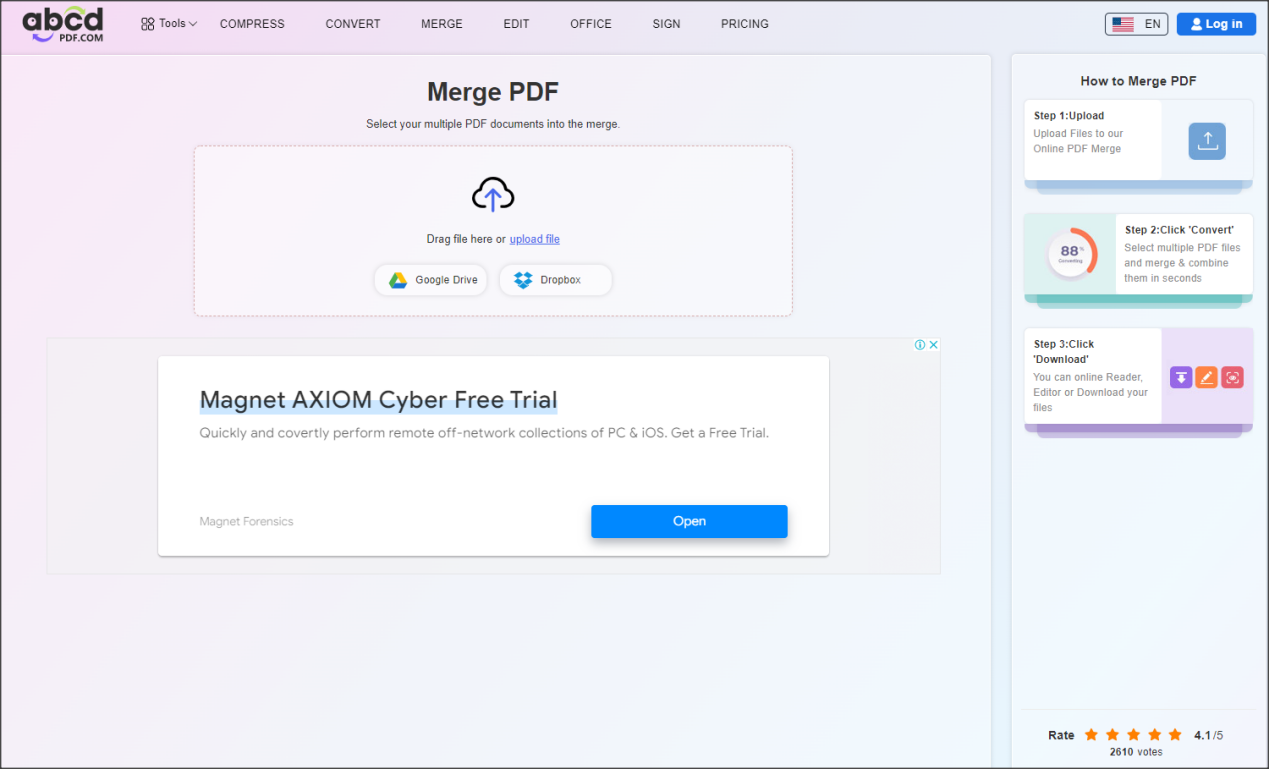
Step 2. Upload the local PDF files that need to be merged, “+” to add multiple documents.
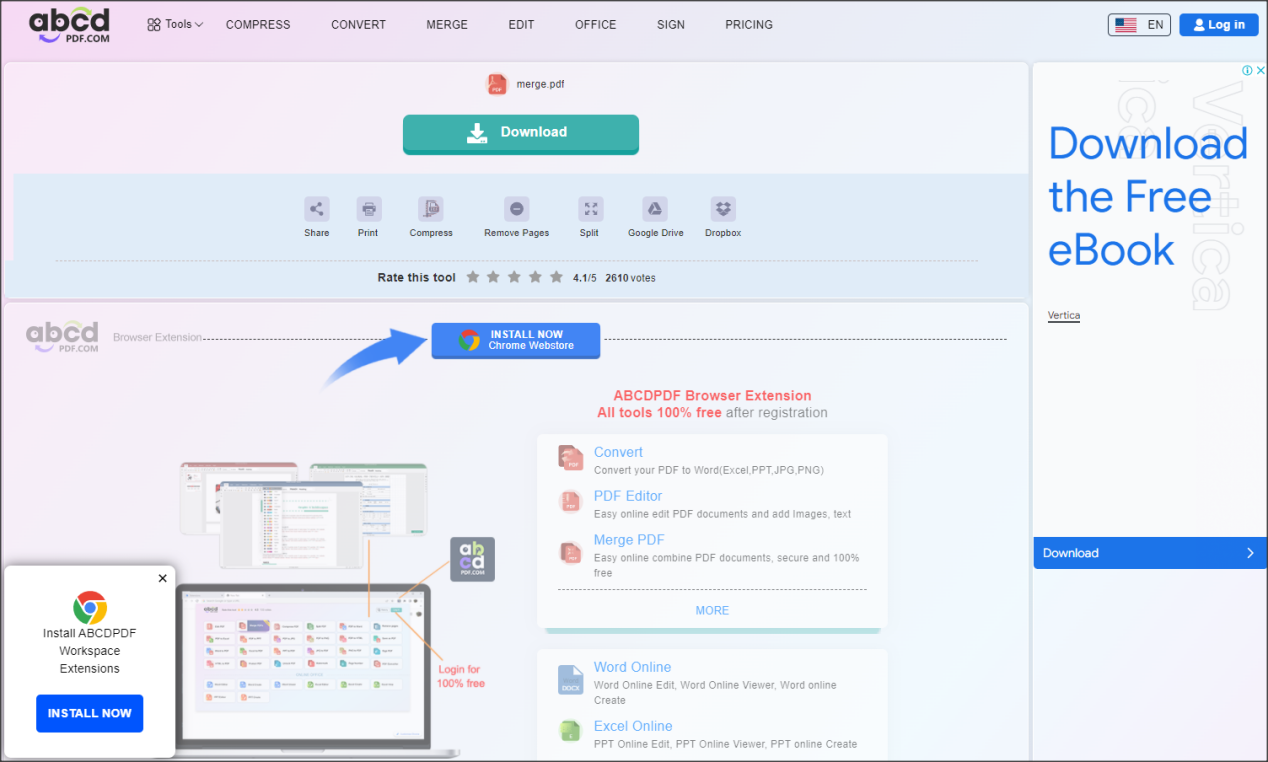
Step 3. After waiting for the merger to complete, click the “Download” button on the page.
Summarize
This article uses Merge PDF as a reference to discuss the problems and solutions encountered by PDF tools when extracting PDF text data. For ordinary users, you can use this free online tool to quickly merge PDF files.